Ariadne
Ariadne is a tool I made to help me discover and organize papers designed around the interaction of citation chasing. It leverages GPU compute to scale interactively to graphs with hundreds of thousands of nodes, allowing users to iteratively populate their graph with papers of interest and expand on connections discovered through exploring the graph.
Motivation
How does a user know what questions they want to ask when learning about a new research topic, or when exploring a new space through data? If we can represent the underlying data as a graph, and explicitly make the structure known to a user, it opens up opportunities for various interactions to take place.
To learn about a topic, you might engage in citation chasing. A typical approach would be to skim the bibliography of a paper, then manually look up papers that piqued your interest. This is both tedious and time consuming. A slightly faster way of citation chasing might be to look at the citations of your starting papers in a research tool like Semantic Scholar or Google Scholar. Then, you could leverage their citation networks to quickly reach those papers that pique your interest instead of having to manually find them.
However, this still loses a useful piece of information – the connections between papers. At first, it might be possible to keep track of how a few papers are related, but as the search progresses the number of papers quickly turns into an unmanageable collection where these connections have to be rediscovered1.
By visualizing the graph structure during the chasing process, it’s possible to see how all the papers are connected, highlighting papers with many links to others in your chase (likely fundamental ideas to your search), or connections between papers you might have missed that warrant a second look.
You could also imagine that this would extend to finding connections between multiple research topics, or making sense of a field of research as a whole.
Approach
Opportunities for novel interactions
Many user interactions have traditionally limited the amount of data presented – either intentionally, to highlight what’s deemed to be most relevant, or due to past computational constraints. While these approaches are effective, I’m instead especially interested in what becomes possible when those limitations are removed. Interactions that work well at small scales don’t always extend to larger datasets, but by building tools that support both, we can combine their strengths, explore hybrid solutions, and discover new interactions adaptable across all scales.
Performance
Ariadne has been built with performance as a primary concern, offloading computation and rendering to the GPU whenever it makes sense to do so. At the time of writing, Ariadne performs graph layout using a GPU-accelerated Barnes-Hut algorithm utilizing a BVH built fully on the GPU. Label placement and text culling is done with compute kernels, and all rendering is done with a custom but fairly standard GPU graphics pipeline. The CPU is mainly delegated to handling user input, fetching data over network, and marshalling data to/from GPU buffers.
Local-first
Aside from the sources providing information about the papers and how they are connected, all processing happens on-device. Once fetched, the data is stored locally for all app interactions. Our personal devices are hugely powerful and doing things locally results in a more responsive experience under a wider variety of conditions, albeit at a hit to the user’s battery life. While I aim to not perform unnecessary and wasteful computations, I am prioritizing responsiveness for now. While this might not be as exciting for others, it’s something important to me.
Examples
Finding connections between multiple topics
Suppose that I know a bit about GPU Programming and a bit about Bounding Volume Hierarchies (BVHs), but I’m not sure about work related to building a BVH on the GPU. We’ll build two initial graphs to start, each from the first page of results (10 papers) on Google Scholar for both search terms. Ariadne will then also pull in those papers’ references and citations to populate the graph.
Our graph for GPU Programming looks like this: 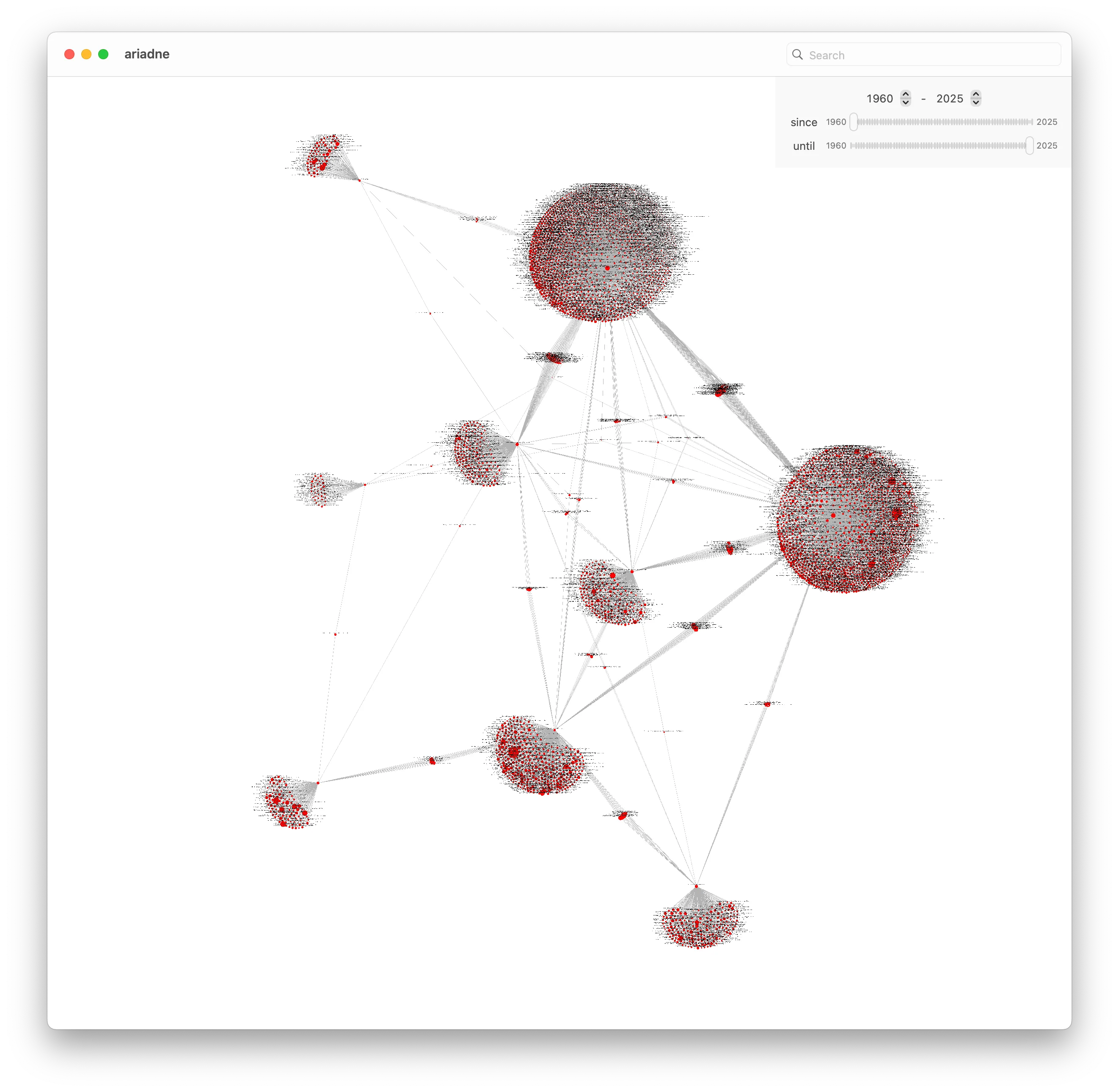
And our graph for Bounding Volume Hierarchies looks like this: 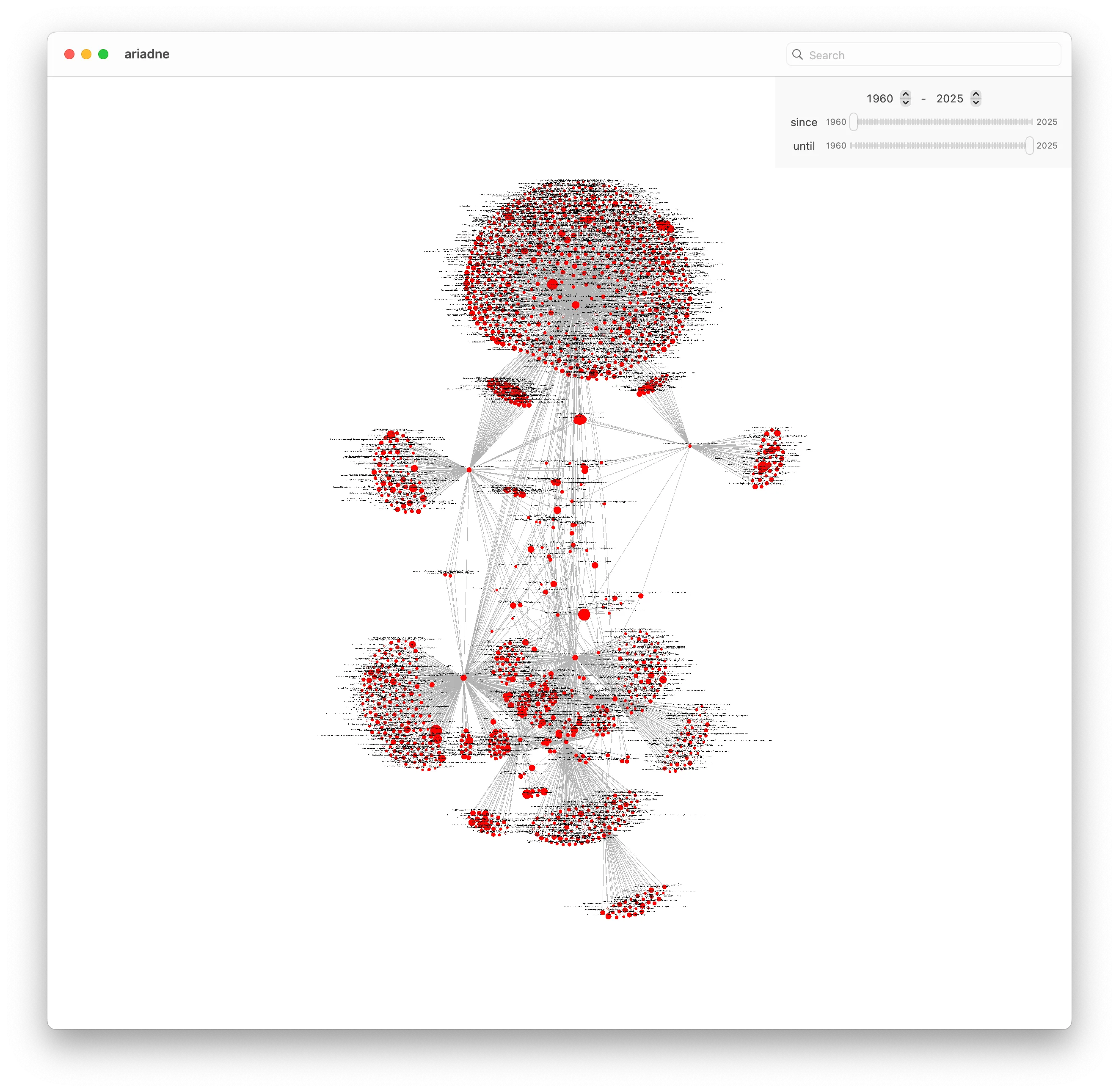
If we combine both graphs, we can see that there are a few papers that link the two graphs we started with (coloring GPU Programming in yellow, and BVH in blue): 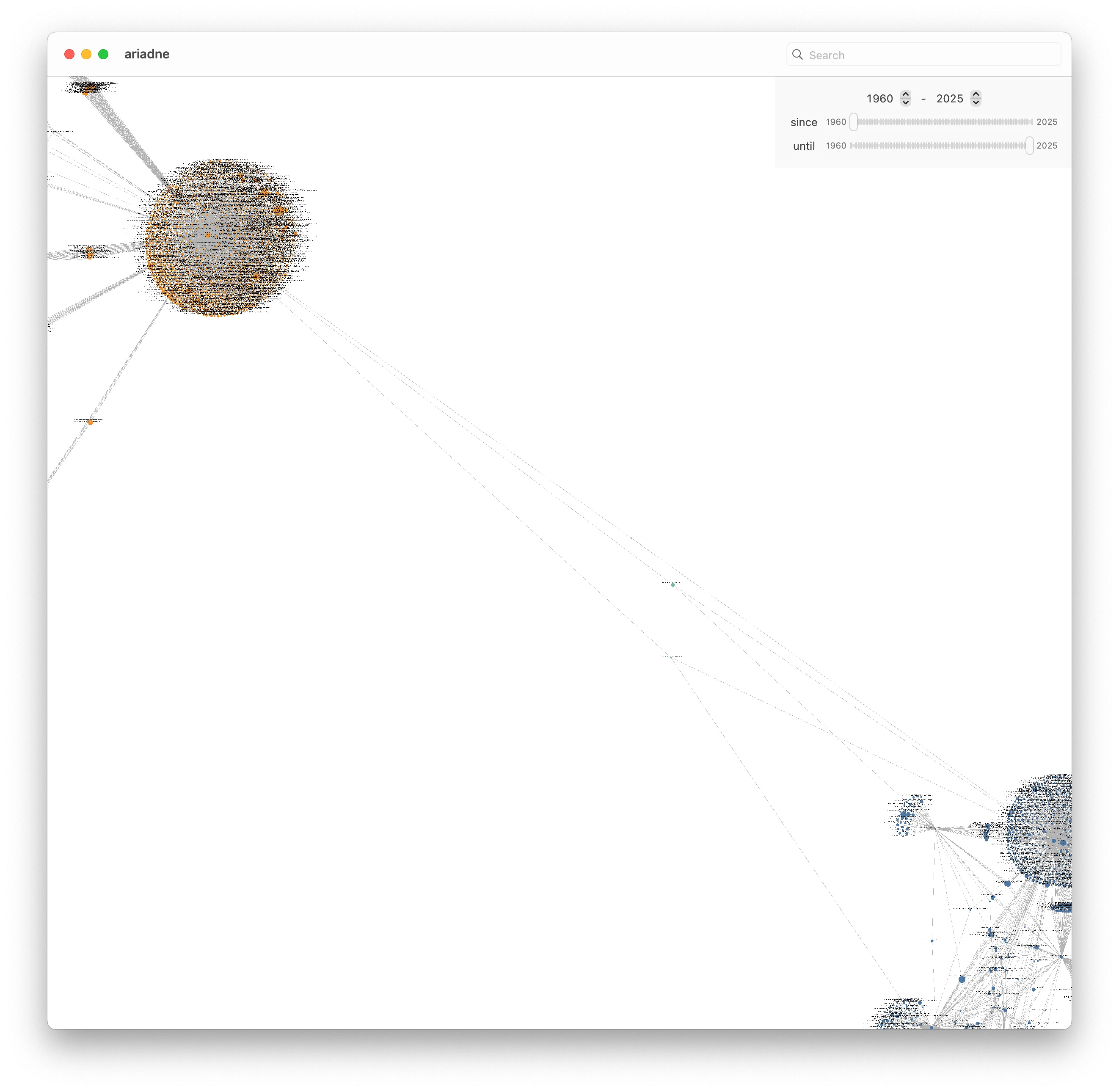
But upon examining which papers in the BVH graph they are connected to, we find two survey papers and another one more generally about collision detection. Useful, but not quite what we’re looking for since I want to find the implementations more directly.
We can get better results by expanding the areas of the graph we’re interested in, so let’s try to expand the BVH graph a bit. Before doing so, there are a lot of papers which might not all be useful for what we want. We’ll start by finding papers that might be more interesting, and try restricting the papers we expand to just those that have at least two connections in our graph: 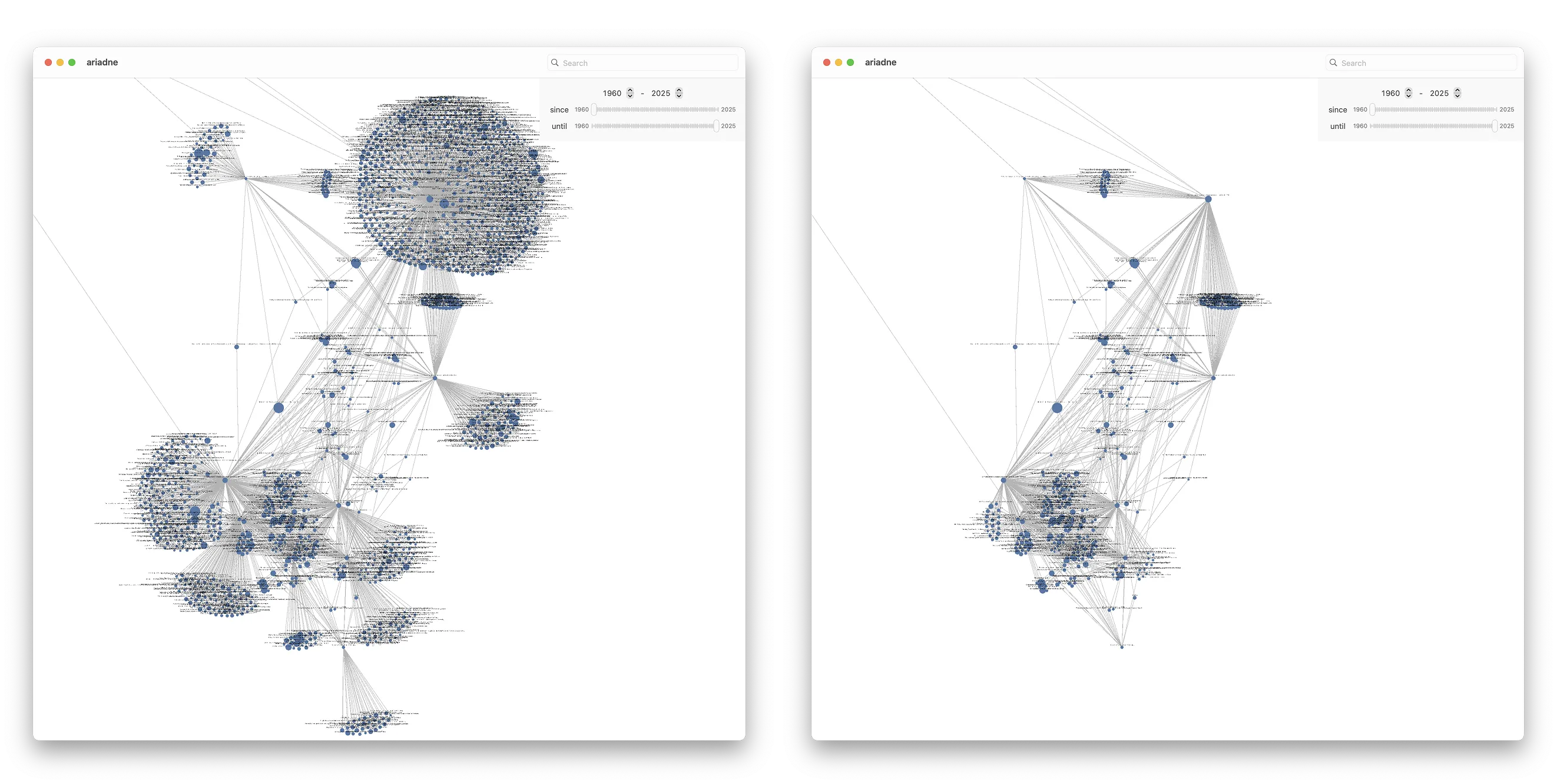
And now that we’ve filtered down to a smaller set, we can expand the graph by fetching all those papers’ references, which in turn should hopefully add more connections to the GPU Programming graph: 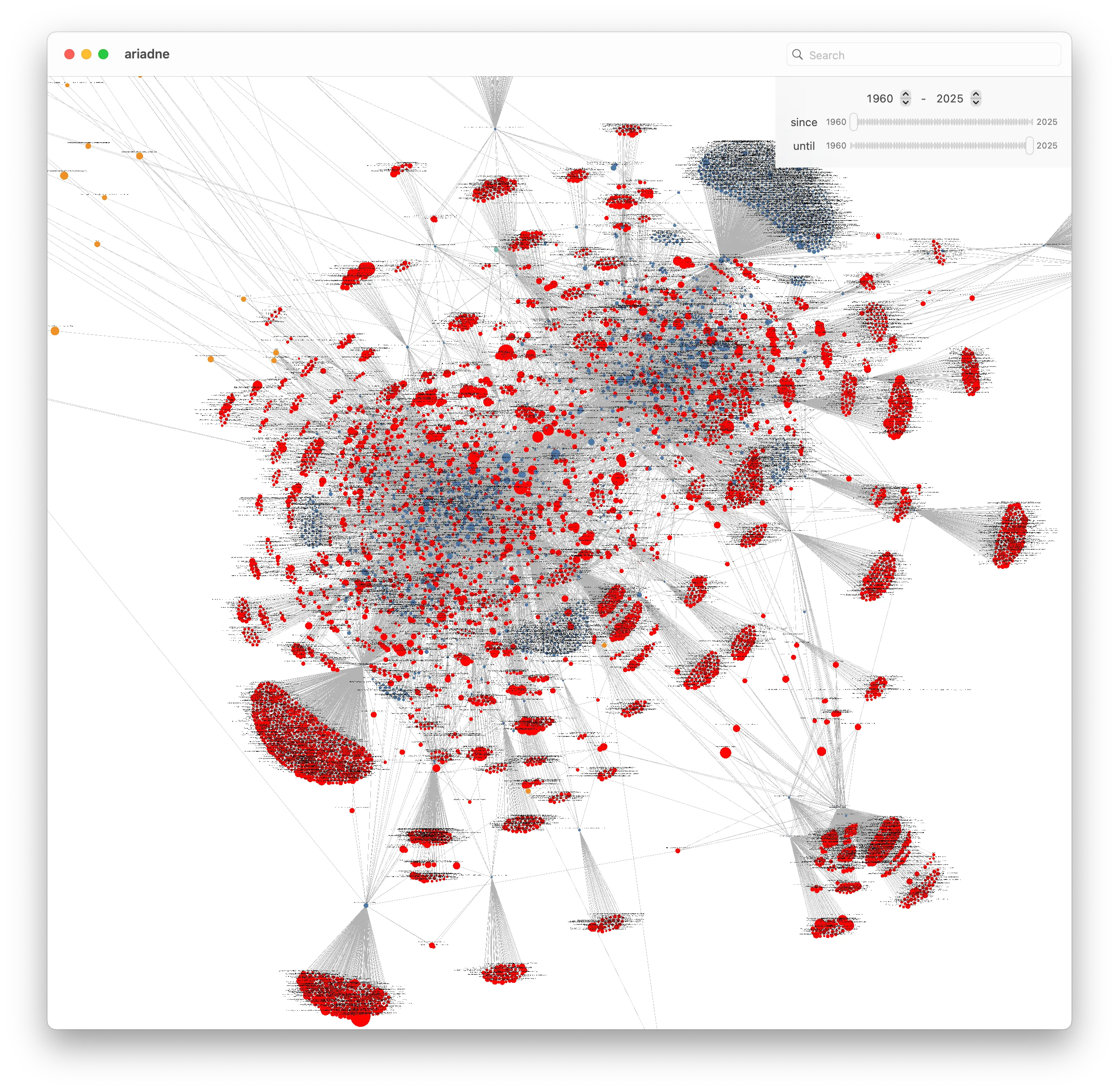
The expanded BVH graph is now a massive hairball that’s difficult to make sense of, but there are still a few things we can do. By selecting all the papers that are bridging the two graphs, we can highlight which papers in the BVH graph they are connected to: 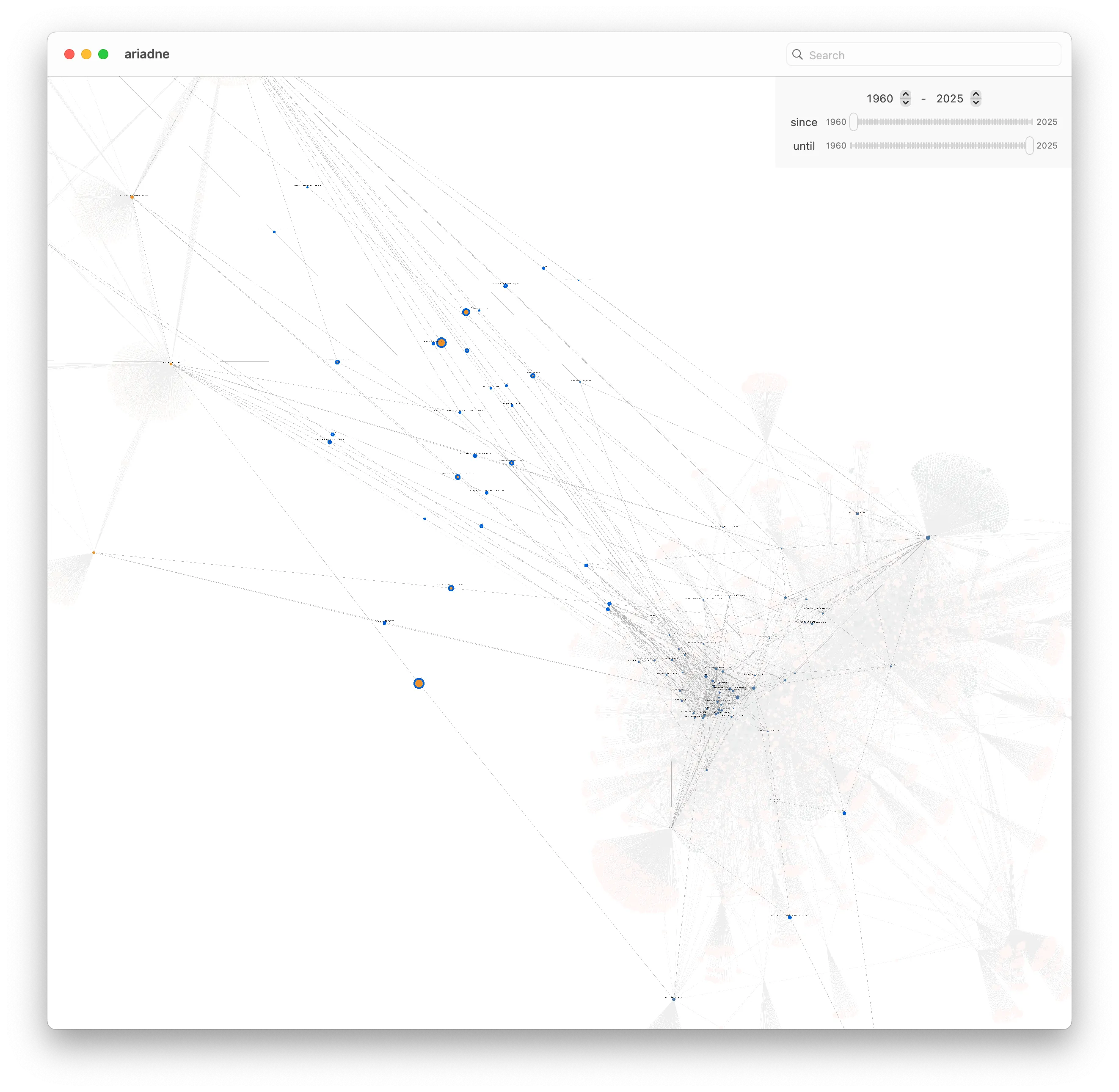
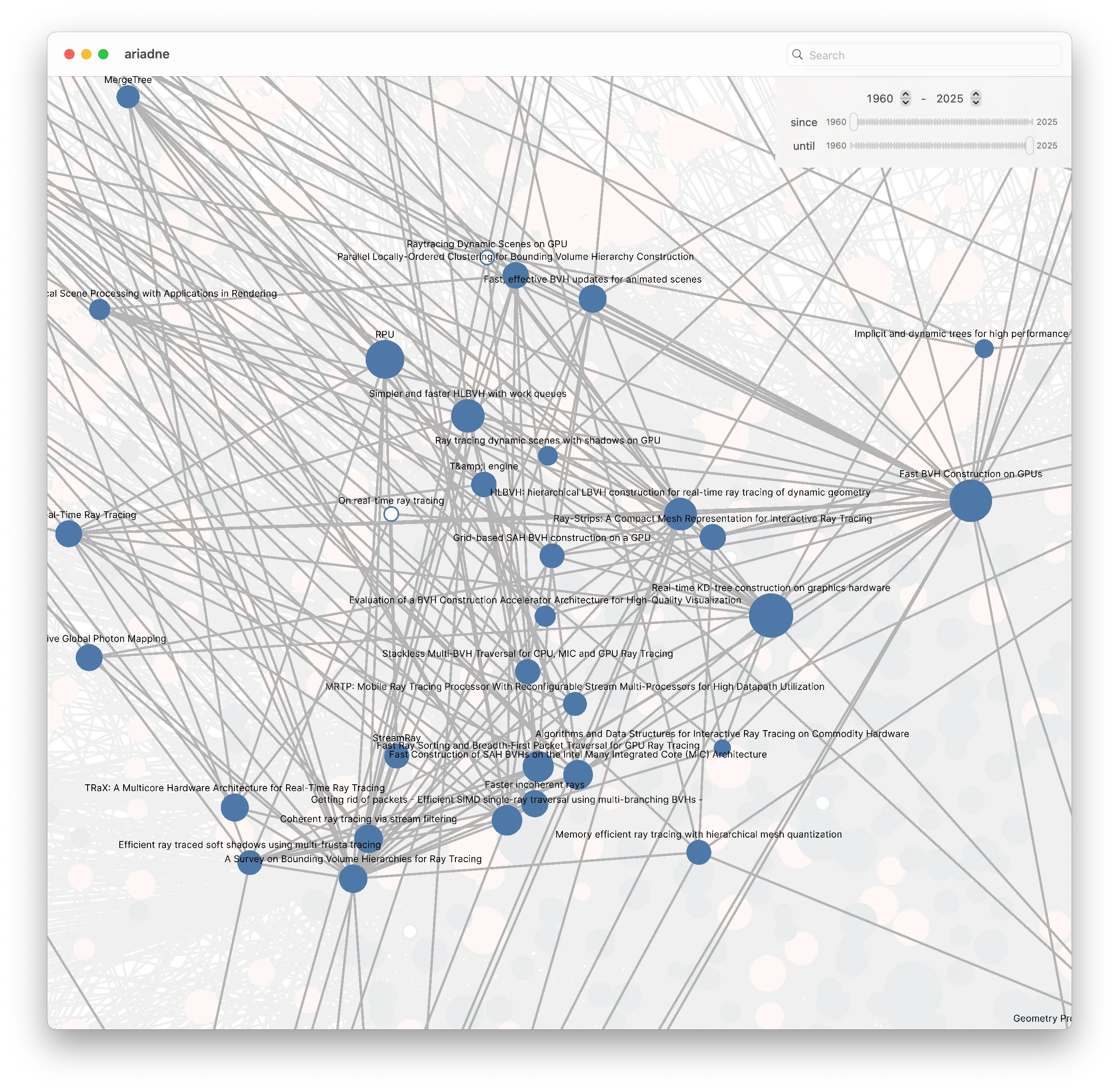
And zooming in to these papers a bit further, I can see some promising results – Fast BVH Construction on GPUs, Parallel Locally Ordered Clustering for Bounding Volume Hierarchy Construction, HLBVH: hierarchical LBVH construction for real-time ray tracing of dynamic geometry, to name a few.
NOTE
There’s one paper here that Google Scholar would have never found, which is Real-time KD-tree construction on graphics hardware. This paper doesn’t have anything to do with a BVH, at least in keywords. But, if you know a little bit about building a BVH, you might know that techniques for building k-d trees can often be adapted to building a BVH. This paper and Fast BVH Construction on GPUs are two of the earliest influential papers in this area of research.
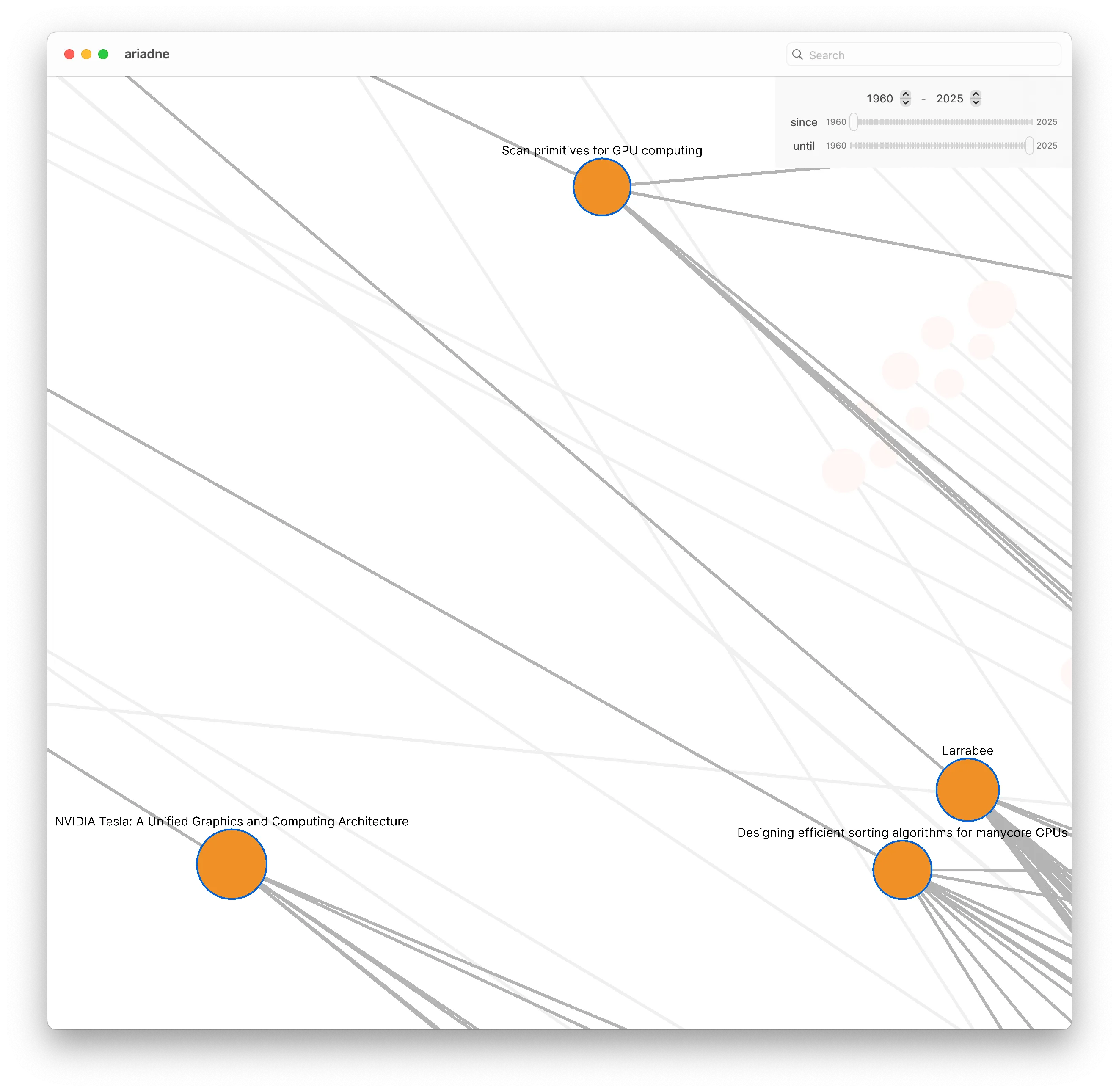
If we zoom out a bit, we might notice that four of the (orange) papers in the GPU Programming graph seem to be closer to the BVH graph than the rest of the bridging papers: 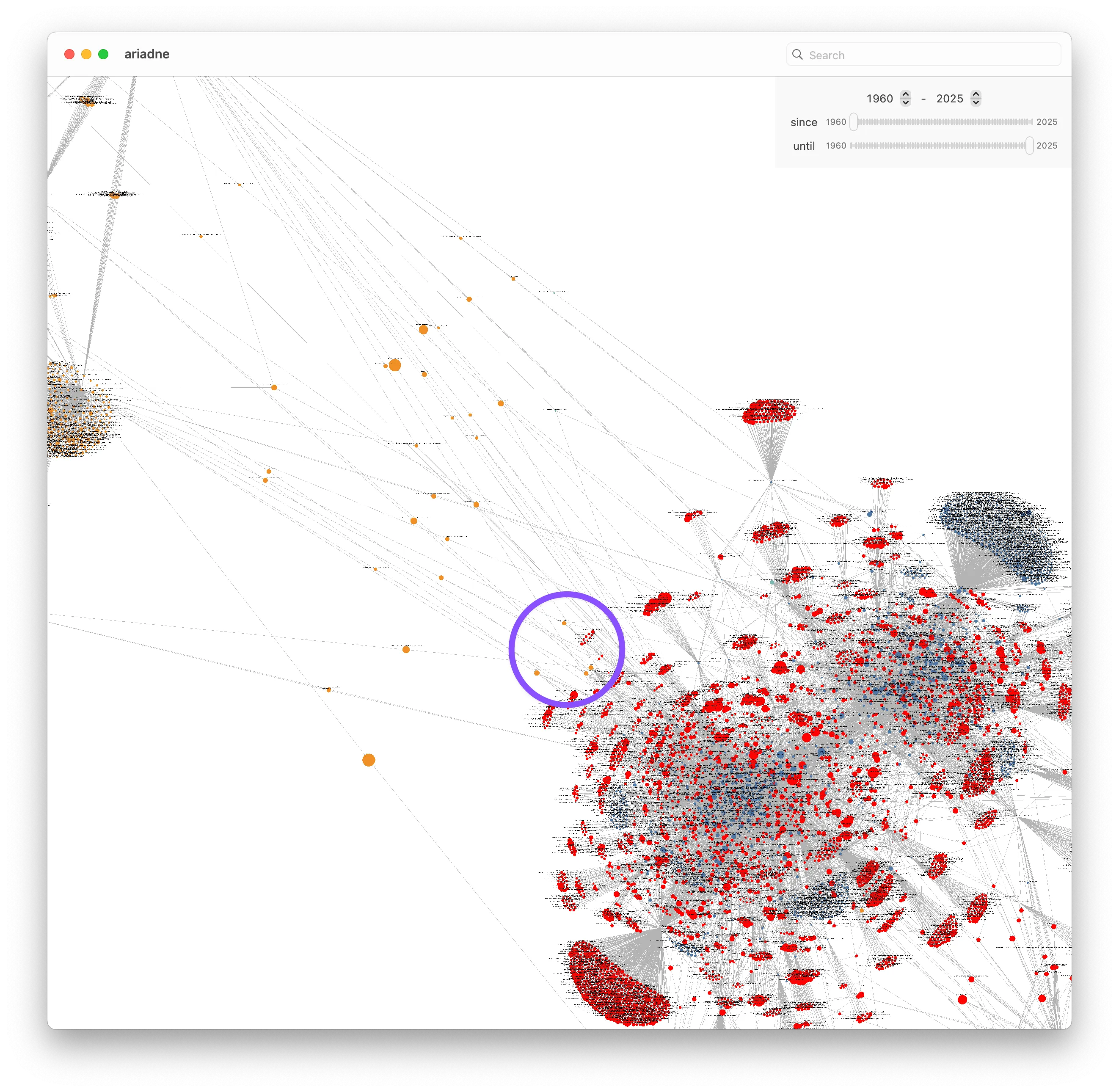
If we look at those four papers in more detail, we can see what they are.
NOTE
In particular, I want to point out Scan primitives for GPU computing and Designing efficient sorting algorithms for manycore GPUs. The proximity of these two papers to the BVH graph is not a coincidence. Many GPU BVH building algorithms rely heavily on performing scans and sorts during various steps of the construction process.
Footnotes
-
ConnectedPapers showcases some of this potential, but limits the size of the graph to only around 40 papers. ↩